机器学习需要多少训练数据?
本文共 756 字,大约阅读时间需要 2 分钟。
机器学习需要多少训练数据?
取决于:
- 所需解决问题的难易程度
- 所采用的模型的复杂程度(模型参数数量)
- 想要达到什么样的性能
① 最快的方法
查找相关领域的论文资料,别人一般用多少的数据量
② 经验范围
回归分析:要训练出一个性能良好的模型,所需训练样本数量应是模型参数数量的10倍。
缺点:
- 稀疏特征:例如稀疏特征的编码是01001001对于模型的训练能够起到作用的特征是少数的,而不起作用的特征占大多数。依照上述线性规则,若模型对于每个特征分配相应的参数,也就是说对于无用的特征也分配了相应的参数,再根据10倍规则法,获取是模型参数数量10倍的训练样本集,此时的训练样本数量对于最佳的训练模型来说可能是超量的,所以,此时用10倍规则法得到的训练样本集未必能够真实地得出好的训练模型。
- 由于正则化和特征选择技术,训练模型中真实输入的特征的数量少于原始特征数量。
计算机视觉:对于使用深度学习的图像分类,经验法则是每一个分类需要 1000 幅图像,如果使用预训练的模型则可以用更少数据去训练。
③ 在分类任务中确定训练数据量的方法
学习曲线是误差与训练数据量的关系图。我们可以建立一个学习曲线的函数,然后采用非线性回归或者加权非线性回归对学习曲线进行拟合,然后找到期望准确率下的样本数量。
④ 样本容量估计(给定统计检验的检验效能,确定样本数量)
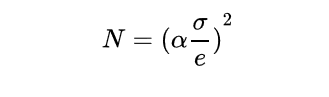
N是所需样本数量,α![]() 一定置信度所对应的的标准正态分布的个数,σ
一定置信度所对应的的标准正态分布的个数,σ![]() 是样本的标准差, e是可接受的误差范围。
是样本的标准差, e是可接受的误差范围。
⑤ 训练数据规模的统计学习理论
VC 维是模型复杂度的度量,模型越复杂,VC 维越大。

N为所需样本数量, d为失效概率, ε![]() 为学习误差。
为学习误差。
⑥ 一般准则
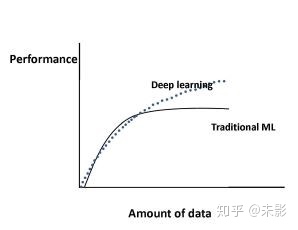
传统的机器学习算法:性能是按照幂律增长的,一段时间后趋于平稳。
深度学习:性能随着数据的增加呈现对数增长
转载地址:http://mzuii.baihongyu.com/
你可能感兴趣的文章
poj 1976 A Mini Locomotive (dp 二维01背包)
查看>>
《计算机网络》第五章 运输层 ——TCP和UDP 可靠传输原理 TCP流量控制 拥塞控制 连接管理
查看>>
《PostgreSQL技术内幕:查询优化深度探索》养成记
查看>>
剑指_复杂链表的复制
查看>>
FTP 常见问题
查看>>
Python学习笔记之数据类型
查看>>
shell 快捷键
查看>>
VIM滚屏操作
查看>>
将file文件内容转成字符串
查看>>
MODULE_DEVICE_TABLE的理解
查看>>
.net强制退出主窗口的方法——Application.Exit()方法和Environment.Exit(0)方法
查看>>
c# 如何调用win8自带的屏幕键盘(非osk.exe)
查看>>
build/envsetup.sh 简介
查看>>
编译Android4.0源码时常见错误及解决办法
查看>>
Android 源码编译make的错误处理
查看>>
启用SELinux时遇到的问题
查看>>
virbr0 虚拟网卡卸载方法
查看>>
No devices detected. Fatal server error: no screens found
查看>>
新版本的linux如何生成xorg.conf
查看>>
Linux基础教程:CentOS卸载KDE桌面
查看>>